Okay, another question from Twitter (original content will have to wait till I get some more free time!)
Here’s the challenge:
Need help with #Azure#AppInsights: when summarizing, I want to adjust the bin size according to the time range the user selects in the Query editor. I found `bin_auto(timestamp)` which looks promising, but still I need to `set query_bin_auto_size=1m` manually. Any clues? pic.twitter.com/TtwCTH5OtR
So what we need to do here is somehow infer the time-range of the query, and then create a fixed set of time bins according to that range.
I think the only way to that is by performing 2 queries – one to get the time range and convert it into a fixed interval, and a second query with the actual logic.
To convert the result of the first query into a ‘variable’ we can use in the second query, I’ll use the ‘toscalar‘ operation.
Here we go:
let numberOfBuckets = 24;
let interval = toscalar(requests
| summarize interval = (max(timestamp)-min(timestamp)) / numberOfBuckets
| project floor(interval, 1m));
requests
| summarize count() by bin(timestamp , interval)
I use ‘floor’ here just to round the interval and make the results a bit more readable.
I’ll keep it short and simple this time. Here’s a great way to debug your app across multiple App Insights instances.
So, I have two Azure Functions services running, with one serving as an API, and the other serving as BE processing engine. Both report telemetry to App Insights (different apps), and I am passing a context along from one to the other – so I can correlate exceptions and bugs.
Wouldn’t it be great to be able to see what happened in a single session across the 2 apps?
It’s possible – using ‘app‘ – just plugin the name of the app insights resource you want to query, and a simple ‘union‘.
Here you go:
let session="reReYiRu";
union app('FE-prod').traces, app('BE-prod').traces
| where session_Id == session
| project timestamp, session_Id, appName, message
| order by timestamp asc
Don’t forget –
You can use the field ‘appName‘ to see which app this particular trace is coming from.
Different machines have different times.. Don’t count on the timestamp ordering to always be correct.
App Insights Analytics just released Smart Diagnostics, and it is by far the best application of Machine Learning analytics in the service to date.
I’ve posted before about some ML features such as autocluster and smart alerting, but this one really takes the cake as the most powerful and useful yet:
It’s super-duper easy to use! Despite the huge complexity of the Machine Learning algo behind the scenes.
It’s fast!
It can give you awesome answers that save you lots of investigation time and agony.
It works by analyzing spikes in charts, and giving you a pattern that explains the sudden change in the data.
So let’s give it a go!
Analyze spike in dependency duration
I run a service that has all kinds of remote dependencies – calls to Azure blobs, queues, http requests, etc.
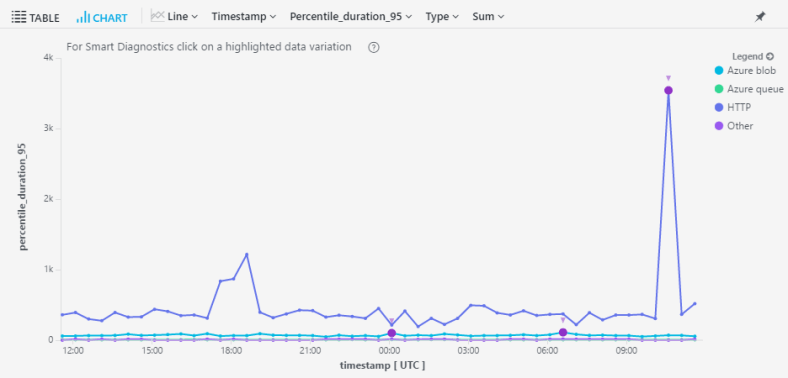
In my devops hat, I run this simple query almost daily just to gauge the health of my service – a look at the 95th percentile for call duration by dependency type:
dependencies
| where timestamp > ago(1d)
| where operation_SyntheticSource == ""
| summarize percentile(duration, 95) by bin(timestamp,30m), type
| render timechart
The results look like this:
Right off the bat I can see something very funky going on in my http calls. I wanna know exactly what’s going on, but drilling in to the raw data can be a messy business.
If only there was a way to analyze that spike with just one click…. !!!
Fortunately, there’s a small purple dot on that spike. It signifies that this spike is available for analysis with Machine Learning (aka Smart Diagnostics).
Once I click on it, the magic happens.
Smart Diagnostics just told me that the cause for the spike in call duration was:
It sounded a lot like a challenge to me, so I just couldn’t resist!!
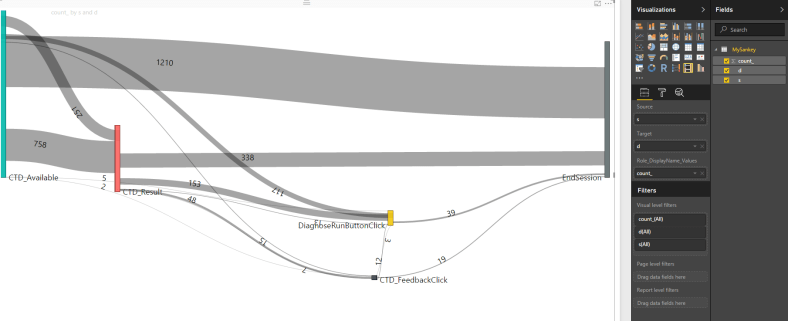
Sankey diagrams for those who don’t know are an amazing tool for describing user flows AND are the basis for one of the most famous data visualizations of all-time. But really, I had no idea how to create one. So, I googled Sankey + PowerBI and came across this fantastic Amir Netz video:
So all you need to create the diagram is a table with 3 columns:
Source
Destination
Count
And PowerBI takes care of the rest.
We already know you can take any App Insights Analytics query and “export” the data to PowerBI.
So the only problem now is how do I transform my AppInsights custom events table into a Sankey events table?
Let’s go to Analytics!
First it’s best to have an idea of what we’re trying to do. Decide on 5-10 events that make sense for a user session flow. In my case, I want to see the flow of users through a new feature called “CTD”. So the events I chose are:
CTD_Available (feature is available for use)
CTD_Result (user used the feature and got a result)
CTD_DrillIn (user chose to further drill-in the results)
CTD_Feedback (user chose to give feedback)
In every step, I’m interested in seeing how many users I’m “losing”, and what they’re doing next.
Ok, let’s get to work!
First query we’ll
Filter out only relevant events
Sort by timestamp asc (don’t forget that in this chart, order is important!)
Summarize by session_id using makelist, to put all events that happened in that session in an ordered list. If you’re unfamiliar with makelist, all it does is take all the values of the column, and stuffs them into a list. The resulting lists are the ordered events that users triggered in each session.
customEvents
| where timestamp > ago(7d)
| where name=="CTD_Available" or name=="CTD_Result" or
name=="CTD_Drillin" or name== "CTD_Feedback"
| sort by timestamp asc
| summarize l=makelist(name) by session_Id
Next step I’ll do is add an “EndSession” event to each list, just to make sure my final diagram is symmetric. You might already have this event as part of your telemetry, I don’t. This is optional, and you can choose to remove this line.
To do this, I need to chop off the first item in the list and “zip” it (like a zipper) with the original list. In c# this is very easy – list.Zip(list.Skip(1))..
Amazingly, App Analytics has a zip command! Tragically, it doesn’t have a skip… :(. Which means we need to do some more ugly regex work in order to chop off the first element.
There’s a pretty nice operator in Kusto (or App Insights Analytics) called top-nested.
It basically allows you to do a hierarchical drill-down by dimensions. Sounds a bit much, but it’s much clearer when looking at an example!
So a simple use for it could be something like getting the top 5 result-codes, and then a drill down for each result code of top 3 request names for each RC.
requests
| where timestamp > ago(1h)
| top-nested 5 of resultCode by count(),
top-nested 3 of name by count()
So I can easily see which operation names are generating the most 404’s for instance.
This is pretty cute, and can be handy for faceting.
But I actually find it more helpful in a couple of other scenarios.
First one is getting a chart of only the top N values. For instance, if I chart my app usage by country, I get a gazillion series of all different countries. How can I easily filter the chart to show just my top 10 countries? Well one way is to do the queries separately, and add a bunch of where filters to the chart…
But top nested can save me all that work:
let top_countries = view()
{
customEvents
| where timestamp > ago(3d)
| top-nested 5 of client_CountryOrRegion by count()
};
top_countries
| join kind= inner
(customEvents
| where timestamp >= ago(3d)
) on client_CountryOrRegion
| summarize count() by bin(timestamp, 1h), client_CountryOrRegion
| render timechart
A beautiful view of just my top 5 countries…
I’ve actually used the same technique for a host of different dimensions (top countries, top pages, top errors etc.), and it can also be useful to filter OUT top values (such as top users skewing the numbers), by changing the join to anti-join.
The second neat scenario is calculating percentages of a whole. For instance – how do you calculate the percentage of traffic per RC daily?
Yeah, you can do this using a summarize and the (newly-added) areachart stacked100 chart kind:
requests
| where timestamp >= ago(3d)
| where isnotempty(resultCode)
| summarize count() by bin(timestamp, 1h), resultCode
| render areachart kind=stacked100
But this only partially solves my problem.
Because ideally, I don’t want to look at all these 200’s crowding my chart. I would like to look at only the 40X’s and 500’s, but still as a percentage of ALL my traffic.
I could do this by adding a bunch of countif(rc=403)/count(), countif(rc=404)/count()… ad nauseum, but this is tiresome + you don’t always know all possible values when creating a query.
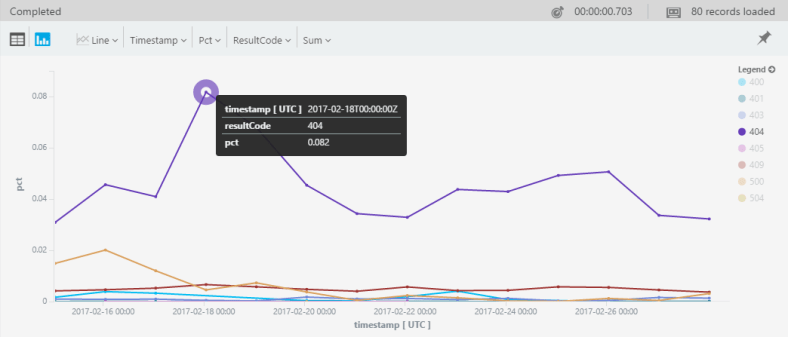
Here’s where top-nested comes in. Because it shows the aggregated value for each level, creating the percentages becomes super-easy. The trick is simply doing the first top-nested by timestamp:
requests
| where timestamp > ago(14d)
| top-nested 14 of bin(timestamp, 1d) by count() ,
top-nested 20 of resultCode by count()
| where resultCode !startswith("20")
| where resultCode !startswith("30")
| project pct=aggregated_resultCode * 1.0 / aggregated_timestamp,
timestamp, resultCode
| render timechart
First the “let” keyword – it basically allows you to bind a name to an expression or to a scalar. This of course is really useful if you plan to re-use the expression.
I’ll give an example that I use in real-life – a basic investigative query into failed requests. I’m joining exceptions and failed dependencies (similar to NRT proactive detection). I’m using the let keyword to easily modify the time range of my query.
Here it is, enjoy!
let investigationStartTime = datetime("2016-09-07");
let investigationEndTime = investigationStartTime + 1d;
requests
| where timestamp > investigationStartTime
| where timestamp < investigationEndTime
| where success == "False"
| join kind=leftouter(exceptions
| where timestamp > investigationStartTime
| where timestamp < investigationEndTime
| project exception=type , operation_Id ) on operation_Id
| join kind=leftouter (dependencies
| where timestamp > investigationStartTime
| where timestamp < investigationEndTime
| where success == "False"
| project failed_dependency=name, operation_Id ) on operation_Id
| project timestamp, operation_Id , resultCode, exception, failed_dependency
I’ve already talked about how cool proactive alerts are, but one thing I missed is that you can actually tweak these alerts through the Azure portal.
Go to the “Alerts” blade, and there you should find a single “Proactive Diagnostics” alert.
If you click it and go to the alert configuration, you can set email recipients, setup a webhook, and enable/disable.
One thing that is really useful is you can set “Received detailed analysis” checkbox:
This will make sure you get the entire deep-dive analysis of the incident straight to your email inbox, without needing to go to the portal. This can save some very valuable minutes during a live-site incident!
Don’t freak out about the title. I’m going to show some powerful machine-learning algorithms behind the scenes — But they are also super-duper easy to use and understand from analytics query results.
I’ll start with Autocluster(). What this operator does, is take all your data, and classify it into clusters. So we’re basically bunching your data into groups. This is very useful in a few scenarios:
Classify request failures – easily see if all failures have a certain response code, are on a certain role instance, a certain operation, or from a specific country etc.
Classify exceptions.
Classify failed dependencies.
This is actually the feature that is being used in the Near Real-Time Proactive Alerts feature to classify the characteristics of the request failure spike.
Let’s get to an example.
I just deployed my service, and checking the portal I see a huge spike in failed requests:
So I know something went terribly wrong, I just don’t know what.
Now, ordinarily what I would do in a situation like this is just take a random failed request, and try to trace the reason it specifically failed. But this can be wrong – several times I just happened to take a failed request that was completely not indicative of the real problem.
So this is where Autocluster() kicks in.
requests
| where success == "False"
| where timestamp > datetime("2016-06-09 14:00")
| where timestamp < datetime("2016-06-09 18:00")
| join (exceptions | project type, operation_Id ) on operation_Id
| project name , cloud_RoleInstance , type
| evaluate autocluster(0.85)
This is basically a query of all the failed requests in the specific timeframe, joined to exceptions. On top of this query I’m running the “evaluate autocluster()” command.
The result I’m expecting is bunching all these records into several groups, which will help me diagnose the common characteristics of my failures.
The results look like this:
!!!
So the autocluster algorithm went over all the data, and found that
71% of the requests failed due to 1 specific exception.
The exception is found on all of my instances – see the “*” in the instance column.
Autocluster just diagnosed the problem in my service, going over thousands of records, in an instant! It’s easy to see why I think this is awesome.
FYI, Autocluster can take in as input any column, even custom dimensions. Ping me in the comments if you have any questions about the usage.
I wanna show two real-world examples (it really happened to me!) of extracting data from traces, and then using that data to get really great insights.
So a little context here – I have a service that reads and processes messages from an Azure Queue. This message processing can fail, causing the same message to be retried many times.
I We recently introduced a bug into the service (as usual.. ) which caused requests to fail on a null reference exception. I wanted to know exactly how many messages were affected by this bug, but it was kind of hard to tell because the retries cause a lot of my service metrics to be off.
Luckily I have a trace just as I am beginning to process a message that shows the message id :










{kind=link}