Ok, so besides App Analytics obviously – one of the most bestest and awesomest new features to come out of App Insights recently has gotta be proactive alerts in near real-time.
It might be the best thing since custom dimensions.
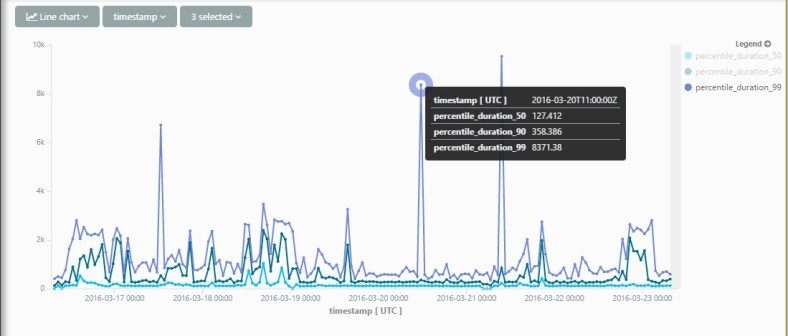
The way it works, AppInsights will auto-magically scan your data, and alert you to anomalies that might be major service issues. The awesome part is
- Absolutely no configuration required. App Insights studies the normal behavior of your service, and finds anomalies from that baseline.
- This could really save your ass! The alert should come-in about 10 minutes from the problem start, usually just in time for a quick fix.
- They’re doing an root cause analysis for you! As you can see in the mail below, the proactive alert correlates exceptions, failed dependencies, traces and every other piece of data in App Insights to try and get you the root cause right in your face.
In the below example, App Insights finds and alerts on a critical problem in my service – and immediately finds the culprit in a failing Http Dependency: