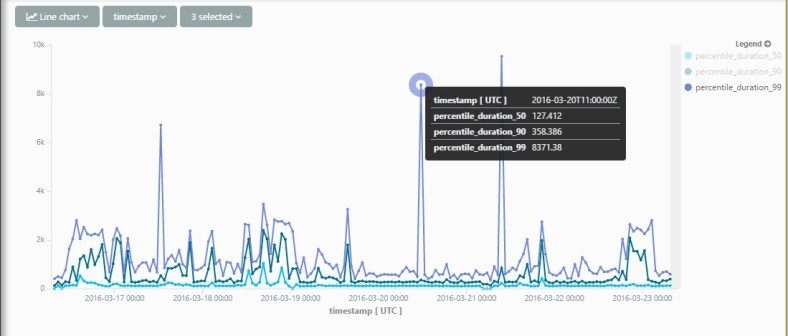
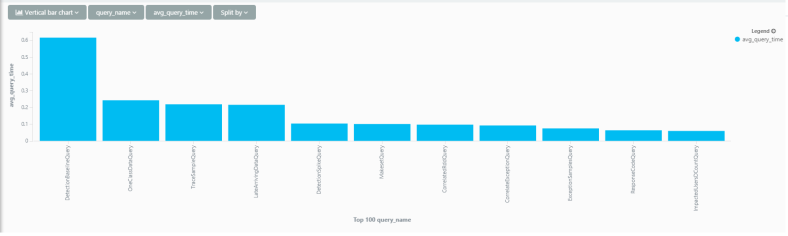
Another cool thing you can do with App Insights Analytics is join different data types to get a good understanding of what’s happening in your app.
A great example are remote dependencies – this is an out-of-the-box feature in App Insights that logs all remote dependency calls such as SQL, Azure, http etc. If you’ve got that data flowing, you can get amazing insights with just a few small queries.
Here’s a small example – Lets’ try and find out which resources are real time-hogs in my service. The query I spun out is – per http request, get the average duration spent calling each dependency type.
requests
| where timestamp > ago(1d)
| project timestamp, operation_Id
| join (dependencies
| where timestamp > ago(1d)
| summarize sum(duration) by operation_Id, type
) on operation_Id
| summarize avg_duration_by_type=avg(sum_duration) by type, bin(timestamp, 20m)
| render barchart